![]()
Classification with Scikit-learn
introml.analyticsdojo.com
20. Classification with Scikit-learn¶
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
20.1. Scikit-learn Interface¶
Scikit-learn strives to have a uniform interface across all methods. Given a scikit-learn estimator
object named model, the following methods are available (not all for each model):
Available in all Estimators
model.fit(): fit training data. For supervised learning applications, this accepts two arguments: the dataXand the labelsy(e.g.model.fit(X, y)). For unsupervised learning applications,fittakes only a single argument, the dataX(e.g.model.fit(X)).
Available in supervised estimators
model.predict(): given a trained model, predict the label of a new set of data. This method accepts one argument, the new dataX_new(e.g.model.predict(X_new)), and returns the learned label for each object in the array.model.predict_proba(): For classification problems, some estimators also provide this method, which returns the probability that a new observation has each categorical label. In this case, the label with the highest probability is returned bymodel.predict().model.decision_function(): For classification problems, some estimators provide an uncertainty estimate that is not a probability. For binary classification, a decision_function >= 0 means the positive class will be predicted, while < 0 means the negative class.model.score(): for classification or regression problems, most (all?) estimators implement a score method. Scores are between 0 and 1, with a larger score indicating a better fit. For classifiers, thescoremethod computes the prediction accuracy. For regressors,scorecomputes the coefficient of determination (R2) of the prediction.model.transform(): For feature selection algorithms, this will reduce the dataset to the selected features. For some classification and regression models such as some linear models and random forests, this method reduces the dataset to the most informative features. These classification and regression models can therefore also be used as feature selection methods.
Available in unsupervised estimators
model.transform(): given an unsupervised model, transform new data into the new basis. This also accepts one argumentX_new, and returns the new representation of the data based on the unsupervised model.model.fit_transform(): some estimators implement this method, which more efficiently performs a fit and a transform on the same input data.model.predict(): for clustering algorithms, the predict method will produce cluster labels for new data points. Not all clustering methods have this functionality.model.predict_proba(): Gaussian mixture models (GMMs) provide the probability for each point to be generated by a given mixture component.model.score(): Density models like KDE and GMMs provide the likelihood of the data under the model.
20.1.1. Intro to Classification¶
To visualize the workings of machine learning algorithms, it is often helpful to study two-dimensional or one-dimensional data, that is data with only one or two features. While in practice, datasets usually have many more features, it is hard to plot high-dimensional data in on two-dimensional screens.
We will illustrate some very simple examples before we move on to more “real world” data sets.
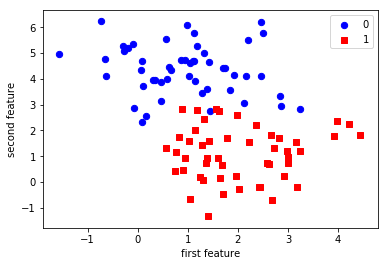
First, we will look at a two class classification problem in two dimensions. We use the synthetic data generated by the make_blobs function.
from sklearn.datasets import make_blobs
X, y = make_blobs(centers=2, random_state=0)
print('X ~ n_samples x n_features:', X.shape)
print('y ~ n_samples:', y.shape)
print('\nFirst 5 samples:\n', X[:5, :])
print('\nFirst 5 labels:', y[:5])
X ~ n_samples x n_features: (100, 2)
y ~ n_samples: (100,)
First 5 samples:
[[ 4.21850347 2.23419161]
[ 0.90779887 0.45984362]
[-0.27652528 5.08127768]
[ 0.08848433 2.32299086]
[ 3.24329731 1.21460627]]
First 5 labels: [1 1 0 0 1]
As the data is two-dimensional, we can plot each sample as a point in a two-dimensional coordinate system, with the first feature being the x-axis and the second feature being the y-axis.
plt.scatter(X[y == 0, 0], X[y == 0, 1],
c='blue', s=40, label='0')
plt.scatter(X[y == 1, 0], X[y == 1, 1],
c='red', s=40, label='1', marker='s')
plt.xlabel('first feature')
plt.ylabel('second feature')
plt.legend(loc='upper right');
#Split the data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.25,
random_state=1234,
stratify=y)
20.1.2. The scikit-learn estimator API¶

Every algorithm is exposed in scikit-learn via an ‘’Estimator’’ object. (All models in scikit-learn have a very consistent interface). For instance, we first import the logistic regression class.
from sklearn.linear_model import LogisticRegression
Next, we instantiate the estimator object.
classifier = LogisticRegression()
X_train.shape
(75, 2)
y_train.shape
(75,)
To built the model from our data, that is to learn how to classify new points, we call the fit function with the training data, and the corresponding training labels (the desired output for the training data point):
classifier.fit(X_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
(Some estimator methods such as fit return self by default. Thus, after executing the code snippet above, you will see the default parameters of this particular instance of LogisticRegression. Another way of retrieving the estimator’s ininitialization parameters is to execute classifier.get_params(), which returns a parameter dictionary.)
We can then apply the model to unseen data and use the model to predict the estimated outcome using the predict method:
prediction = classifier.predict(X_test)
We can compare these against the true labels:
print(prediction)
print(y_test)
[1 0 1 0 1 1 1 1 1 1 1 0 0 0 0 1 0 0 1 0 0 0 1 1 0]
[1 1 1 0 1 1 0 1 1 0 1 0 0 0 0 1 0 0 1 0 0 1 1 1 0]
We can evaluate our classifier quantitatively by measuring what fraction of predictions is correct. This is called accuracy:
np.mean(prediction == y_test)
0.83999999999999997
There is also a convenience function , score, that all scikit-learn classifiers have to compute this directly from the test data:
classifier.score(X_test, y_test)
0.83999999999999997
It is often helpful to compare the generalization performance (on the test set) to the performance on the training set:
classifier.score(X_train, y_train)
0.94666666666666666
LogisticRegression is a so-called linear model, that means it will create a decision that is linear in the input space. In 2d, this simply means it finds a line to separate the blue from the red:
Estimated parameters: All the estimated model parameters are attributes of the estimator object ending by an underscore. Here, these are the coefficients and the offset of the line:
print(classifier.coef_)
print(classifier.intercept_)
[[ 1.38092515 -1.49993172]]
[ 1.54995538]
20.2. Another classifier: K Nearest Neighbors¶
Another popular and easy to understand classifier is K nearest neighbors (kNN). It has one of the simplest learning strategies: given a new, unknown observation, look up in your reference database which ones have the closest features and assign the predominant class.
The interface is exactly the same as for LogisticRegression above.
from sklearn.neighbors import KNeighborsClassifier
This time we set a parameter of the KNeighborsClassifier to tell it we only want to look at one nearest neighbor:
knn = KNeighborsClassifier(n_neighbors=1)
We fit the model with out training data
knn.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
knn.score(X_test, y_test)
1.0